JDBC
简介
JDBC,全称是 Java DataBase Connectivity。
- JDBC 即使用 Java 语言来访问 关系型数据库(MySQL、Oracle) 的一套 API。
- JDBC 是一种标准,JDBC 标准提供的接口存在于
java.sql包中。在这个包中定义有 数据库的连接标准、数据库的操作标准 以及 数据库结果集的处理标准。每个数据库厂商会提供各自的 JDBC 实现,程序员只需要面向接口和标准编程,不需要关心具体实现。

| 接口/类 | 作用 |
|---|---|
| Driver | 驱动接口 |
| DriverManager | 工具类,用于管理驱动,可以获取数据库的链接 |
| Connection | 表示 Java 与数据库建立的连接对象(接口) |
| PreparedStatement | 预编译对象,用于发送 SQL 语句的工具 |
| ResultSet | 结果集,用于获取查询语句的结果 |
JDBC 执行流程

环境搭建
执行以下 SQL 语句创建 atguigudb 数据库和 user 用户表,为后续的 JDBC 操作搭建一个测试环境。
CREATE DATABASE IF NOT EXISTS atguigudb;
use atguigudb;
CREATE TABLE IF NOT EXISTS `user` (
`uid` BIGINT(32) AUTO_INCREMENT COMMENT '主键列(自动增长)',
`name` VARCHAR(32) NOT NULL COMMENT '用户名称',
`age` INT(3) NOT NULL COMMENT '用户年龄',
`birthday` DATE NOT NULL COMMENT '用户生日',
`salary` FLOAT DEFAULT 15000.0 COMMENT '用户月薪',
`note` TEXT COMMENT '用户说明',
CONSTRAINT pk_uid PRIMARY KEY (`uid`)
) COMMENT '用户表';获取连接
驱动
java.sql.Driver 接口是所有驱动程序需要实现的接口。这个接口是提供给数据库厂商使用的,不同的数据库厂商提供不同的实现。其中,加载驱动由 Java SPI 机制实现,无需再像以前一样使用 Class.forName("com.mysql.driver") 来加载 MySQL 驱动。
Tip
对于 Java SPI 不清楚的小伙伴可以查看 SPI机制详解 这一篇文章,文章中详细地介绍了 Java SPI 机制的由来、原理以及应用。
URL
URL 用于标识一个被注册的驱动程序,从而建立到数据库的连接。URL 的标准由三部分组成,各部分之间用冒号分隔:
- 协议:java 的连接 URL 中的协议总是 jdbc
- 子协议:子协议用于标识一个数据库驱动程序
- 子名称:一种标识数据库的方法。子名称作用是为了 定位数据库。其包含 主机名 (对应服务器的 ip 地址),端口号、数据库名
MySQL 的连接 URL 编写方式:jdbc:mysql://主机名称:mysql 服务端口号/数据库名称?参数=值&参数=值。
一个完整的 URL="jdbc:mysql://localhost:3306/atguigudb?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimeze=Asia/Shanghaion"。
useUnicode=true&characterEncoding=utf-8的作用是指定字符的编码、解码格式。若 MySQL 数据库用到的是 GBK 的编码方式,而项目数据使用的是 UTF-8 的编码方式,这时如果添加了该参数则会在存取数据时根据 MySQL 和项目的编码方式将数据进行相应的格式转化。即:数据库在存项目数据时,会先将 UTF-8 格式数据解码成字节码,然后再将字节码重新使用 GBK 编码存到数据库中。在从数据库取数据时,会先将数据库中的数据按 GBK 格式解码成字节码,然后再将字节码重新按 UTF-8 格式编码数据,最后再将数据返回给客户端。- MySQL5.7 之后要加上
useSSL=false,MySQL5.7 以及之前的版本则不用添加,默认为 false。useSSL=true通过证书或者令牌进行安全验证,SSL 协议服务主要提供:认证用户服务器,确保数据发送到正确的服务器;加密数据,放置数据传输途中被窃取使用;维护数据完整性,验证数据在传输过程中是否丢失。 - MySQL8.0 之后必须加上
serverTimezone=Asia/Shanghai,指定当前服务器所处的时区。
用户名密码
建立数据库连接时必须的参数,其中的用户名和密码由自己保管,务必不要告诉他人。
测试
- 在资源目录
resources下新建db.properties配置文件,用于维护数据库连接 URL、用户名和密码信息。 - 编写测试类
JdbcTests。
jdbc.url=jdbc:mysql://localhost:3306/atguigudb?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
jdbc.username=root
jdbc.password=123456public class JdbcTests {
private static final Logger LOGGER = LoggerFactory.getLogger(JdbcTest.class);
private static Connection CONNECTION = null;
@BeforeEach
public void before() {
try (InputStream inputStream = JdbcTest.class.getClassLoader().getResourceAsStream("db.properties")) {
Properties properties = new Properties();
properties.load(inputStream);
String url = properties.getProperty("jdbc.url");
String username = properties.getProperty("jdbc.username");
String password = properties.getProperty("jdbc.password");
CONNECTION = DriverManager.getConnection(url, username, password);
LOGGER.info("【建立数据库连接】:{}", CONNECTION);
} catch (IOException | SQLException e) {
throw new RuntimeException(e);
}
}
@AfterEach
public void after() {
if (CONNECTION != null) {
try {
CONNECTION.close();
LOGGER.info("【关闭数据库连接】:{}", CONNECTION);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
@Test
public void testConnection() {
}
}测试结果如下所示:获取到 MySQL 连接实例对象,以及使用完成后及时关闭连接。Connection 的使用原则是尽量晚创建,尽量早释放。
Statement 接口
更新 - 添加数据
@Test
public void testAdd() throws SQLException {
Statement statement = connection.createStatement();
String sql = "INSERT INTO `user`(`name`, `age`, `birthday`, `salary`, `note`) VALUES('小让', 18, '1995-07-13', 16000.0, '程序员');";
int count = statement.executeUpdate(sql);
LOGGER.info("【数据更新行数】:{}", count);
}测试结果如下所示:【数据更新行数】:1 
在 MySQL 客户端中执行 select * from user; 语句查看表中全部数据。
更新 - 删除数据
@Test
public void testDelete() throws SQLException {
Statement statement = connection.createStatement();
String sql = "DELETE FROM `user` WHERE `uid` = 1;";
int count = statement.executeUpdate(sql);
LOGGER.info("【数据更新行数】:{}", count);
}测试结果如下所示:【数据更新行数】:1 
再次利用 MySQL 客户端执行 select * from user; 语句查看表中全部数据,发现刚刚插入进去的一条的数据已被成功删除。
查询数据
- 在执行查询前先往
user表中插入几条数据,这样可以保证等下查询出来的效果。 - 创建用户类
User。 - 编写测试代码
JdbcTests#testQuery()。
INSERT INTO `user`(`name`, `age`, `birthday`, `salary`, `note`) VALUES('小让', 18, '1995-07-13', 16000.0, '程序员');
INSERT INTO `user`(`name`, `age`, `birthday`, `salary`, `note`) VALUES('小星', 18, '1995-03-20', 20000.0, '幼教');
INSERT INTO `user`(`name`, `age`, `birthday`, `salary`, `note`) VALUES('三十', 25, '1995-08-08', 22000.0, '硬件工程师');@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
/**
* 主键列
*/
private Integer uid;
/**
* 姓名
*/
private String name;
/**
* 年龄
*/
private Integer age;
/**
* 生日
*/
private Date birthday;
/**
* 工资薪水
*/
private Float salary;
/**
* 说明
*/
private String note;
}@Test
public void testQuery() throws SQLException {
Statement statement = connection.createStatement();
String sql = "SELECT * FROM `user`;";
ResultSet rs = statement.executeQuery(sql);
while (rs.next()) {
int uid = rs.getInt("uid");
String name = rs.getString("name");
int age = rs.getInt("age");
Date birthday = rs.getDate("birthday");
float salary = rs.getFloat("salary");
String note = rs.getString("note");
User user = new User(uid, name, age, birthday, salary, note);
LOGGER.info("{}", user);
}
}测试结果如下所示: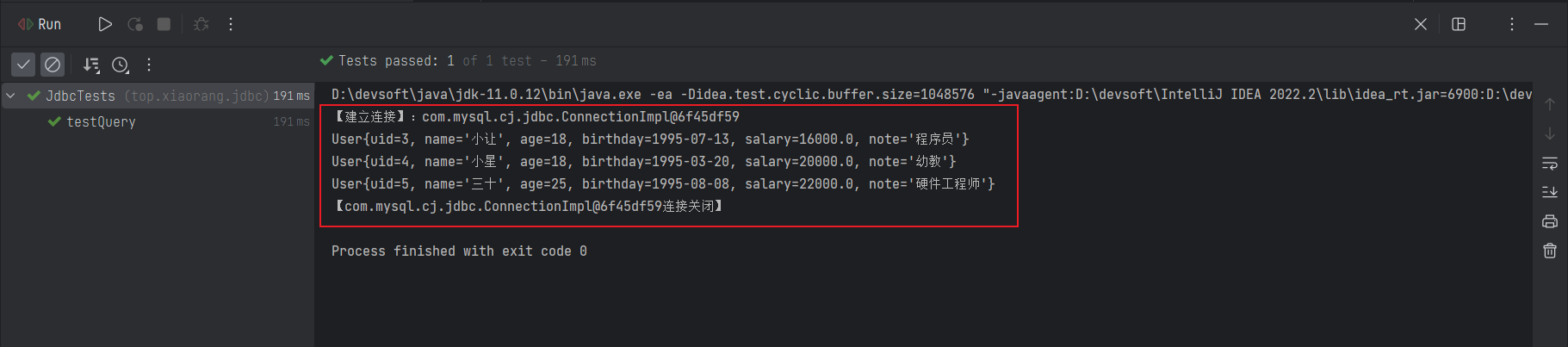
再次利用 MySQL 客户端执行 select * from user; 语句查看表中全部数据。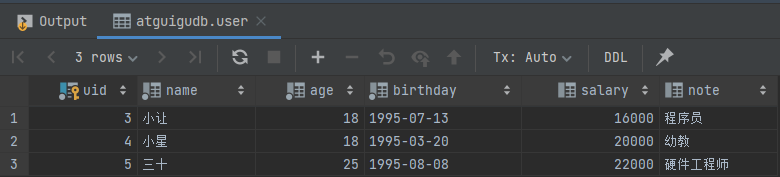
💣SQL 注入
由于 Statement 使用的是拼接的 SQL 语句,所以很容易出现 SQL 注入 问题。那么何为 SQL 注入呢?SQL 注入指的是某些系统没有对用户输入的数据进行充分的检查,而在用户输入数据中注入非法的 SQL 语句段或命令,从而利用系统的 SQL 引擎完成恶意行为的做法。
咱们可以写一个简单的案例来测试一下:查询是否存在 ' 小白 ' 的用户,正常情况下用户表中是查询不到任何叫小白的用户的。
@Test
public void testSQLInjection() throws SQLException {
Statement statement = connection.createStatement();
String username = "'小白'";
String sql = "SELECT * FROM `user` where `name` = " + username;
ResultSet rs = statement.executeQuery(sql);
while (rs.next()) {
int uid = rs.getInt("uid");
String name = rs.getString("name");
int age = rs.getInt("age");
Date birthday = rs.getDate("birthday");
float salary = rs.getFloat("salary");
String note = rs.getString("note");
System.out.println("User{" +
"uid=" + uid +
", name='" + name + '\'' +
", age=" + age +
", birthday=" + birthday +
", salary=" + salary +
", note='" + note + '\'' +
'}');
}
}测试结果如下所示:的确查询不到叫 ' 小白 ' 的用户。
但是此时,咱们将测试代码修改一下,让其中的 username = ' 小白 ' or 1 = 1
@Test
public void testSQLInjection() throws SQLException {
Statement statement = connection.createStatement();
String username = "'小白' or 1 = 1";
String sql = "SELECT * FROM `user` where `name` = " + username;
ResultSet rs = statement.executeQuery(sql);
while (rs.next()) {
int uid = rs.getInt("uid");
String name = rs.getString("name");
int age = rs.getInt("age");
Date birthday = rs.getDate("birthday");
float salary = rs.getFloat("salary");
String note = rs.getString("note");
System.out.println("User{" +
"uid=" + uid +
", name='" + name + '\'' +
", age=" + age +
", birthday=" + birthday +
", salary=" + salary +
", note='" + note + '\'' +
'}');
}
}测试结果如下所示:可以查询到用户表中的全部数据。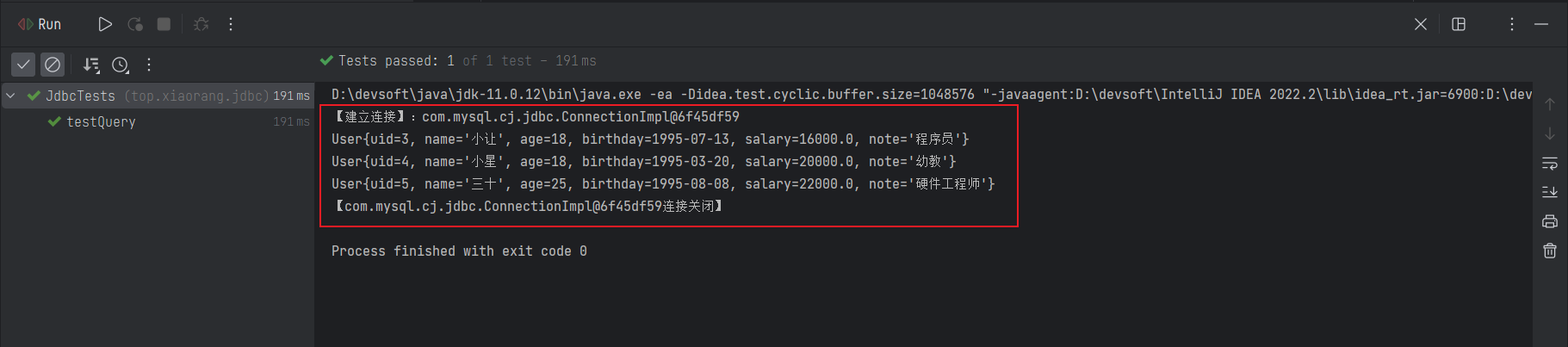
可以想象一下如果在登录系统的时候也使用 SQL 注入的手段,那么岂不是任何一个人无需用户名和密码都可以登录进系统,这是一件多么可怕的事情!那么有没有办法解决该问题呢?答案肯定是有的,此时就引出咱们即将学到的 PreparedStatement 接口。
PreparedStatement 接口
MySQL 预编译
通常咱们发送一条 SQL 语句给 MySQL 服务器时,MySQL 服务器每次都需要对这条语句进行校验、解析等操作。如下图所示: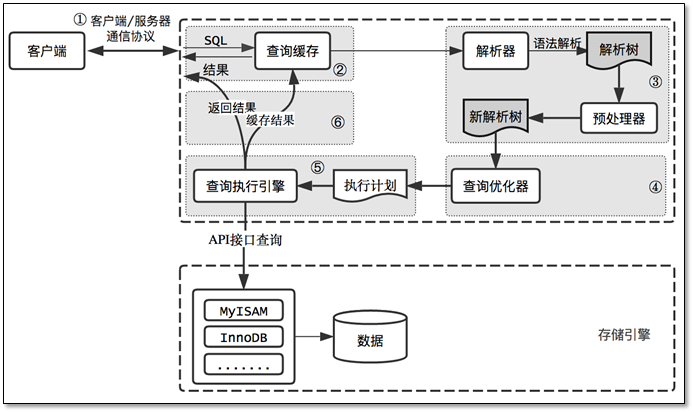
但是很多情况下,一条 SQL 语句可能需要反复的执行,每次执行可能仅仅是传递的参数不同而已,类似于这样的 SQL 语句如果每次都需要进行校验、解析等操作,未免太过于浪费性能,因此产生了 SQL 语句的预编译。所谓预编译就是将一些灵活的参数值以占位符 ? 的形式给替代掉,把参数值给抽取出来,把 SQL 语句进行模板化。让 MySQL 服务器执行相同的 SQL 语句时,不再需要在校验、解析 SQL 语句上面花费重复的时间。
如何使用预编译呢?
- 定义预编译 SQL 语句
prepare statement from 'select * from user where uid = ? and name = ?';- 设置参数值
set @uid = 4,@name='小星';- 执行预编译 SQL 语句
execute statement using @uid,@name;运行结果如下所示:
🔥PreparedStatement
可以通过 Connection 连接对象的 prepareStatement(sql) 方法获取 PreparedStatement 实例对象,其中,PreparedStatement 接口继承自 Statement 接口,方法中的参数 sql 表示一条预编译过的 SQL 语句,在 SQL 语句中的参数值用占位符 ? 来表示,之后可以使用 setXxx() 或者 setObject() 方法来设置这些参数,💡需要注意的是,索引值从 1 开始。
更新 - 添加数据
@Test
public void testPreparedStatementAdd() throws SQLException {
String sql = "INSERT INTO `user`(`name`, `age`, `birthday`, `salary`, `note`) VALUES(?, ?, ?, ?, ?);";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.setString(1, "小白");
preparedStatement.setInt(2, 18);
preparedStatement.setDate(3, new Date(new java.util.Date().getTime()));
preparedStatement.setFloat(4, 18000.0f);
preparedStatement.setString(5, "销售");
int count = preparedStatement.executeUpdate();
System.out.println("【数据更新行数】:" + count);
}测试结果如下所示:【数据更新行数】:1 
在 MySQL 客户端中执行 select * from user; 语句查看表中全部数据。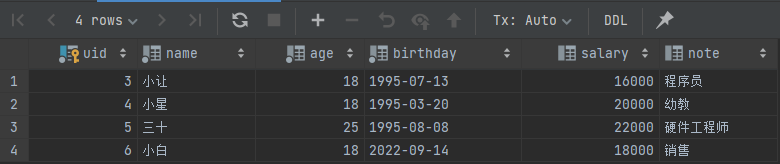
更新 - 删除数据
@Test
public void testPreparedStatementDelete() throws SQLException {
String sql = "DELETE FROM `user` WHERE `uid` = ?;";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.setInt(1, 6);
int count = preparedStatement.executeUpdate();
System.out.println("【数据更新行数】:" + count);
}测试结果如下所示:【数据更新行数】:1 
在 MySQL 客户端中执行 select * from user; 语句查看表中全部数据,发现刚刚插入进去的一条的数据已被成功删除。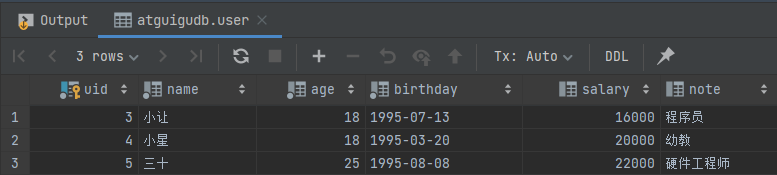
查询数据
@Test
public void testPreparedStatementQuery() throws SQLException {
String sql = "SELECT * FROM `user` WHERE `name` like ?;";
try (PreparedStatement preparedStatement = CONNECTION.prepareStatement(sql)) {
preparedStatement.setString(1, "%%");
try (ResultSet rs = preparedStatement.executeQuery()) {
while (rs.next()) {
int uid = rs.getInt("uid");
String name = rs.getString("name");
int age = rs.getInt("age");
Date birthday = rs.getDate("birthday");
float salary = rs.getFloat("salary");
String note = rs.getString("note");
User user = new User(uid, name, age, birthday, salary, note);
LOGGER.info("{}", user);
}
}
}
}测试结果如下所示: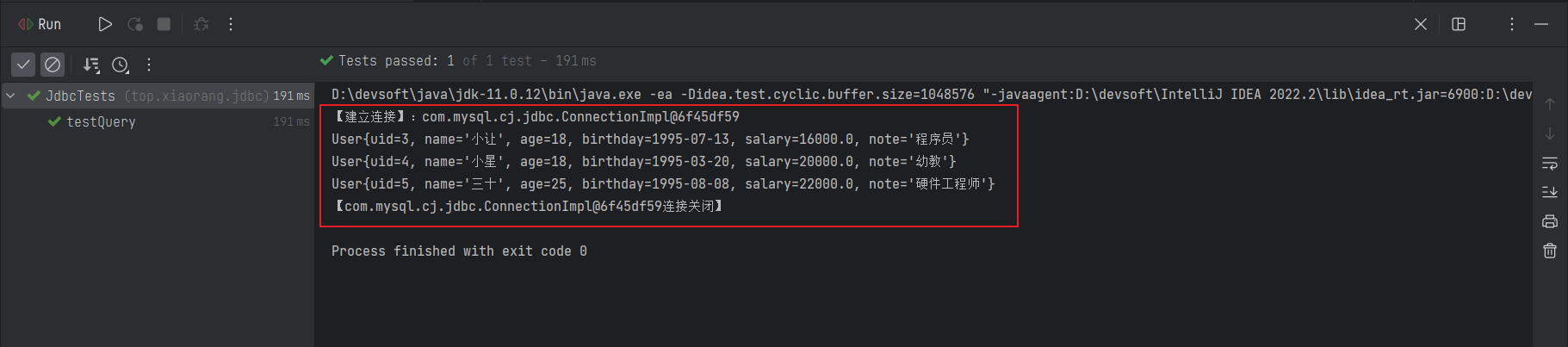
再次利用 MySQL 客户端执行 select * from user; 语句查看表中全部数据。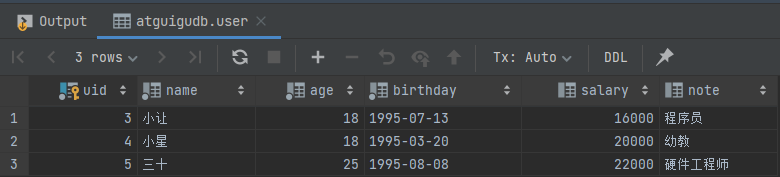
💣问题
事实上,在使用 PreparedStatement 时默认是不能执行预编译的,需要在 URL 中增加额外参数 useServerPrepStmts=true(MySQL Server 4.1 之前的版本是不支持预编译的,而 MySQL Connector 在 5.0.5 以后的版本默认是不开启预编译功能的)。需要注意的是💡,当使用不同的 PreparedStatement 对象来执行相同的 SQL 语句时,还是会出现编译两次的现象,这是因为驱动没有缓存编译后的函数 key,会二次编译。如果希望缓存编译后函数的 key,那么就还需要增加一个参数 cachePrepStmts=true。URL 添加参数之后才能保证 MySQL 驱动先把 SQL 语句发送给服务器进行预编译,然后再执行 executeQuery() 时只是把参数发送给服务器。执行流程如下:
为了查看效果,不妨打开 MySQL 的通用查询日志:
#查看general_log是否开启
show variables like 'general_log%';
#开启general log:
set global general_log = 1;
#查询日志时区
show variables like 'log_timestamps';
#修改日志时区为系统默认的时区,如果想永久修改时区,则在my.ini配置文件中的[mysqld]下增加log_timestamps=SYSTEM
set global log_timestamps=SYSTEM;
# 查看mysql数据存储目录
show global variables like '%datadir%';执行 testPreparedStatementQuery() 测试方法,查看 MySQL 数据存储目录下的 general_log_file 所对应的日志文件,发现执行的 SQL 语句依然是普通的 SQL 语句:
在 URL 上增加参数 useServerPrepStmts=true&cachePrepStmts=true,再次执行 testPreparedStatementQuery() 测试方法,再次查看日志文件,发现日志如下,确实成功开启预编译功能。
防止 SQL 注入
使用 PreparedStatement 可以防止 SQL 注入,其根本原因就是 MySQL 已经对使用了占位符的 SQL 语句进行了预编译,执行计划中的条件已经确定,不能再额外添加其他条件,从而避免了 SQL 注入。
咱们使用 PreparedStatement 的方式再来测试一下上面的 SQL 注入案例,看看是否可以查到名字叫 ' 小白 ' 的用户。
@Test
public void testPreparedStatementSQLInjection() throws SQLException {
String sql = "SELECT * FROM `user` WHERE `name` = ?";
PreparedStatement preparedStatement = CONNECTION.prepareStatement(sql);
preparedStatement.setString(1, "'小白' or 1 = 1");
try (ResultSet rs = preparedStatement.executeQuery()) {
while (rs.next()) {
int uid = rs.getInt("uid");
String name = rs.getString("name");
int age = rs.getInt("age");
Date birthday = rs.getDate("birthday");
float salary = rs.getFloat("salary");
String note = rs.getString("note");
User user = new User(uid, name, age, birthday, salary, note);
LOGGER.info("{}", user);
}
}
}测试结果如下所示:就是以 SQL 注入的方式也查询不到任何数据,成功!
查看日志可以发现,它把传入进行的参数值当成一个整体的字符串作为条件。
批处理
批处理允许将相关的 SQL 语句分组到一个批处理中,并通过一次调用将它们提交到数据库。当你一次向数据库发送多条 SQL 语句时,可以减少通信开销,从而提高性能。
JDBC 驱动程序不一定支持该功能,可以使用 DatabaseMataData.supportsBacthUpdates() 方法来确定目标数据库是否支持批处理更新。如果 JDBC 驱动程序支持此功能,则该方法返回值为 true。
@Test
public void testSupportsBatchUpdates() throws SQLException {
DatabaseMetaData databaseMetaData = CONNECTION.getMetaData();
boolean supportsBatchUpdates = databaseMetaData.supportsBatchUpdates();
System.out.println("是否支持批处理?" + supportsBatchUpdates);
}运行测试代码,发现居然报错!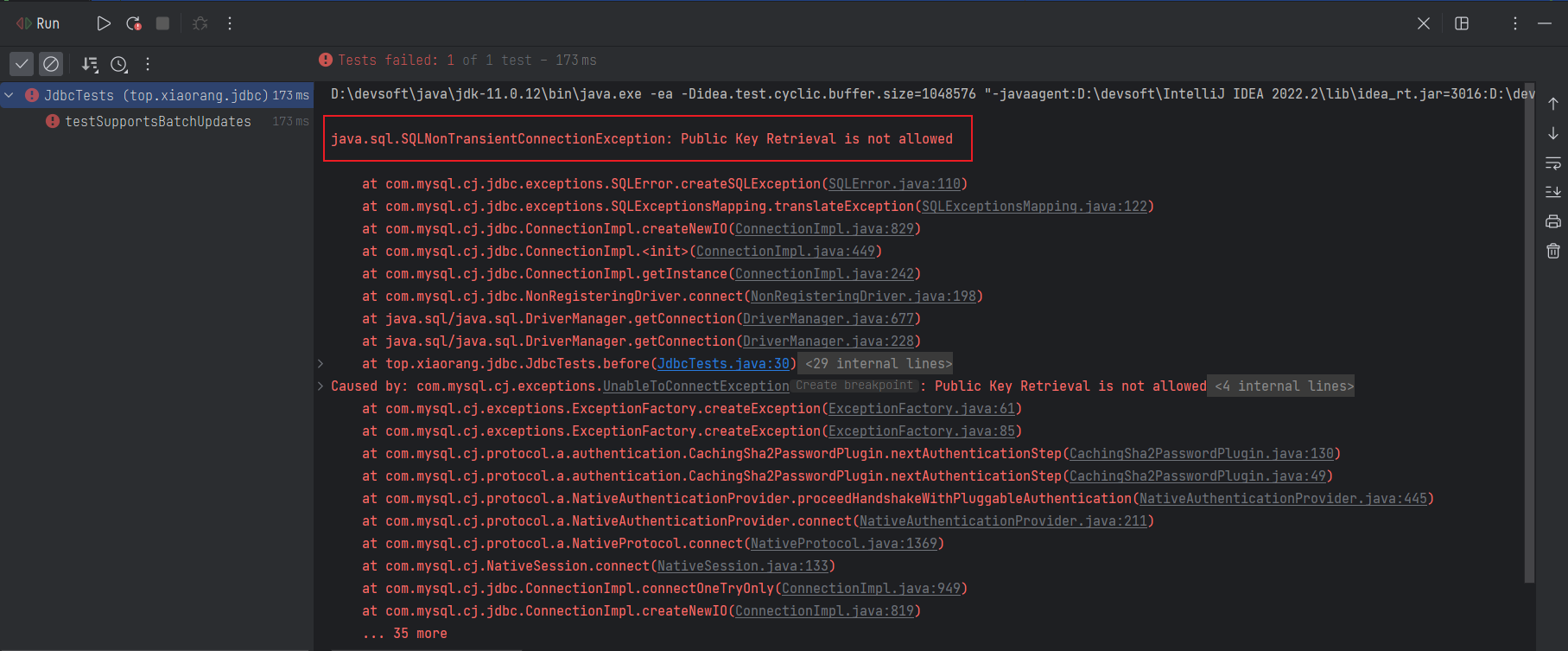
上网一查,发现 MySQL8.x 版本还需在 URL 上加上 allowPublicKeyRetrieval=true 参数。咱们加上,再试一次,发现 MySQL 是支持批处理功能的。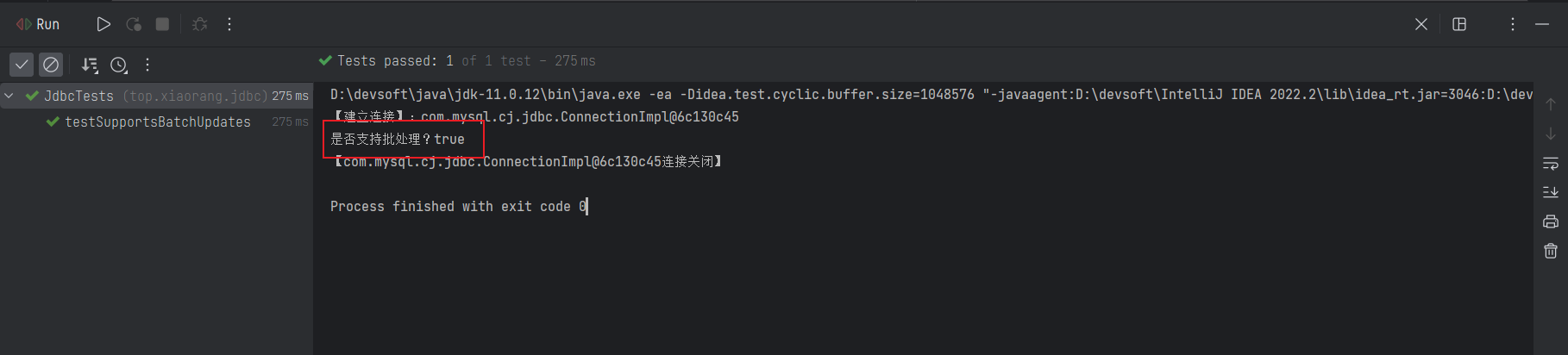
Statement、PreparedStatement、CallableStatement 的 addBatch() 方法用于将单个 SQL 语句添加到批处理中。
excuteBatch() 方法用于执行所有放入批处理中的 SQL 语句。excuteBatch() 方法返回一个整数数组,数组中的每个元素代表各自更新语句的更新数目。
正如将 SQL 语句添加到批处理当中一样,可以使用 clearBatch() 方法清空,该方法用于清空所有添加到批处理当中的 SQL 语句,而无法指定要删除某条数据。
PreparedStatement 批处理
使用 PreparedStatement 实例对象进行批处理的典型步骤顺序如下:
- 使用占位符创建 SQL 语句
- 使用
Connection实例对象的prepareStatement()方法获取PreparedStatement实例对象 - 使用
Connection实例对象的setAutoCommit(false)方法关闭自动提交,即取消自动提交事务 (在下面章节会详细介绍)。 - 使用
PreparedStatement实例对象的setXxx()方法给占位符赋值之后再使用addBatch()方法将 SQL 语句添加到批处理中 - 使用
PreparedStatement实例对象的executeBatch()方法执行批处理 - 最后,使用
Connection实例对象commit()方法提交所有的更改,或者出现异常时,使用rollback()方法回滚所有操作。
@Test
public void testPreparedStatementBatchAdd() {
try {
CONNECTION.setAutoCommit(false);
String sql = "INSERT INTO `user`(`name`, `age`, `birthday`, `salary`, `note`) VALUES(?, ?, ?, ?, ?);";
try (PreparedStatement preparedStatement = CONNECTION.prepareStatement(sql)) {
for (int i = 0; i < 5; i++) {
preparedStatement.setString(1, "小白" + i);
preparedStatement.setInt(2, 18);
preparedStatement.setDate(3, new Date(new java.util.Date().getTime()));
preparedStatement.setFloat(4, 18000.0f);
preparedStatement.setString(5, "销售");
preparedStatement.addBatch();
}
int[] counts = preparedStatement.executeBatch();
CONNECTION.commit();
LOGGER.info("【数据更新行数】:{}", counts);
}
} catch (SQLException e) {
e.printStackTrace();
try {
CONNECTION.rollback();
} catch (SQLException ex) {
throw new RuntimeException(ex);
}
}
}点击测试,发现插入还是挺快的,那么到底有没有用上批处理功能呢?咱们来查看一下 MySQL 日志信息,发现 SQL 语句还是一条一条发送的,并没有使用批处理功能!
不卖关子了,其实还需要在 URL 中增加一个参数 rewriteBatchedStatements=true。
Tip
URL 上只有加上这个参数,并保证 MySQL 驱动在 5.1.13 以上版本,才能实现高性能的批量插入。MySQL 驱动在默认情况下会无视 executeBatch() 语句,把咱们期望批量执行的一组 SQL 语句拆散,一条一条地发给 MySQL 服务器,批量插入直接编程单条插入,所以造成较低的性能。另外,这个参数对 INSERT / UPDATE / DELETE 都有效。
咱们在 URL 上添加上该参数 rewriteBatchedStatements=true 后,再来测试一下,再看看 MySQL 的日志信息。惊讶地发现,程序居然报错了!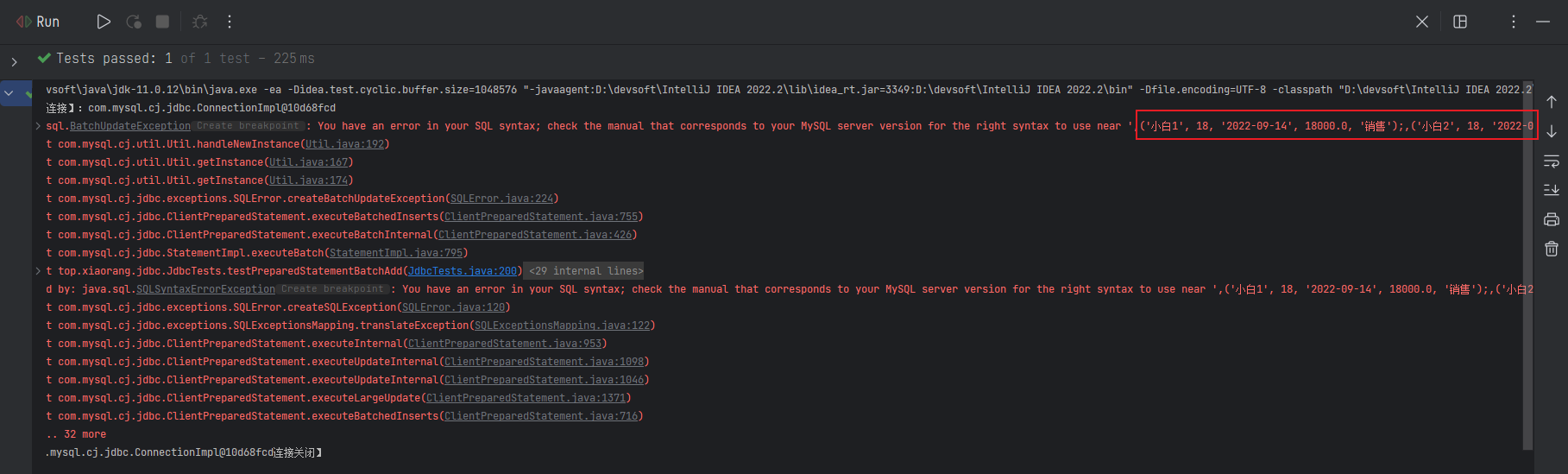
其实细心的小伙伴可以发现,在咱们的 SQL 语句最后有一个分号,这样在做批处理的时候就会出现上图中的错误,所以咱们需要把 SQL 语句最后的分号去掉。
@Test
public void testPreparedStatementBatchAdd() {
try {
CONNECTION.setAutoCommit(false);
String sql = "INSERT INTO `user`(`name`, `age`, `birthday`, `salary`, `note`) VALUES(?, ?, ?, ?, ?)";
try (PreparedStatement preparedStatement = CONNECTION.prepareStatement(sql)) {
for (int i = 0; i < 5; i++) {
preparedStatement.setString(1, "小白" + i);
preparedStatement.setInt(2, 18);
preparedStatement.setDate(3, new Date(new java.util.Date().getTime()));
preparedStatement.setFloat(4, 18000.0f);
preparedStatement.setString(5, "销售");
preparedStatement.addBatch();
}
int[] counts = preparedStatement.executeBatch();
CONNECTION.commit();
LOGGER.info("【数据更新行数】:{}", counts);
}
} catch (SQLException e) {
e.printStackTrace();
try {
CONNECTION.rollback();
} catch (SQLException ex) {
throw new RuntimeException(ex);
}
}
}再来测试一把,发现执行成功,此时再来看看 MySQL 的日志信息,发现达到预期效果!
优化
由于 JDBC 批处理利用的是 SQL 中 INSERT INTO ... VALUES 的方式插入多条数据,所以当以这种方式插入大量的 (几百万或者几千万) 数据时,可能会出现如下异常:
com.mysql.cj.jdbc.exceptions.PacketTooBigException: Packet for query is too large (99,899,527 > 67,108,864). You can change this value on the server by setting the 'max_allowed_packet' variable.max_allowed_packet 为数据包消息缓存区最大大小,单位为字节,默认值为 67108864(64M),最大值 1073741824(1G),最小值 1024(1K),参数值须为 1024 的倍数,非倍数将四舍五入到最接近的倍数。数据包消息缓存区初始大小为 net_buffer_length 个字节,每条 SQL 语句和它的参数都会产生一个数据包消息缓存区,跟事务无关。
如何查看与设置 max_allowed_packet 参数?
# 查看数据包消息缓存区初始大小
show variables like 'net_buffer_length';
# 查看数据包消息缓存区最大大小
show variables like 'max_allowed_packet';
# 重新打开数据库连接参数生效,数据库服务重启后参数恢复为默认,想永久修改的话,则在my.ini配置文件中的[mysqld]下增加max_allowed_packet=32*1024*1024
set global max_allowed_packet=32*1024*1024;咱们为了测试效果,将该值设置小一点,set global max_allowed_packet=20*1024*10; 设置成 200K 大小之后,编写测试代码。
@Test
public void testPreparedStatementBatchAdd2() throws SQLException {
try {
CONNECTION.setAutoCommit(false);
String sql = "INSERT INTO `user`(`name`, `age`, `birthday`, `salary`, `note`) VALUES(?, ?, ?, ?, ?)";
try (PreparedStatement preparedStatement = CONNECTION.prepareStatement(sql)) {
for (int i = 1; i <= 1000000; i++) {
preparedStatement.setString(1, "小白" + i);
preparedStatement.setInt(2, 18);
preparedStatement.setDate(3, new Date(new java.util.Date().getTime()));
preparedStatement.setFloat(4, 18000.0f);
preparedStatement.setString(5, "销售");
preparedStatement.addBatch();
}
int[] counts = preparedStatement.executeBatch();
CONNECTION.commit();
LOGGER.info("【数据更新行数】:{}", counts);
}
} catch (SQLException e) {
e.printStackTrace();
try {
CONNECTION.rollback();
} catch (SQLException ex) {
throw new RuntimeException(ex);
}
}
}插入一百万条数据,点击测试,发现程序报错,报错的信息就和咱们上面提到的一样。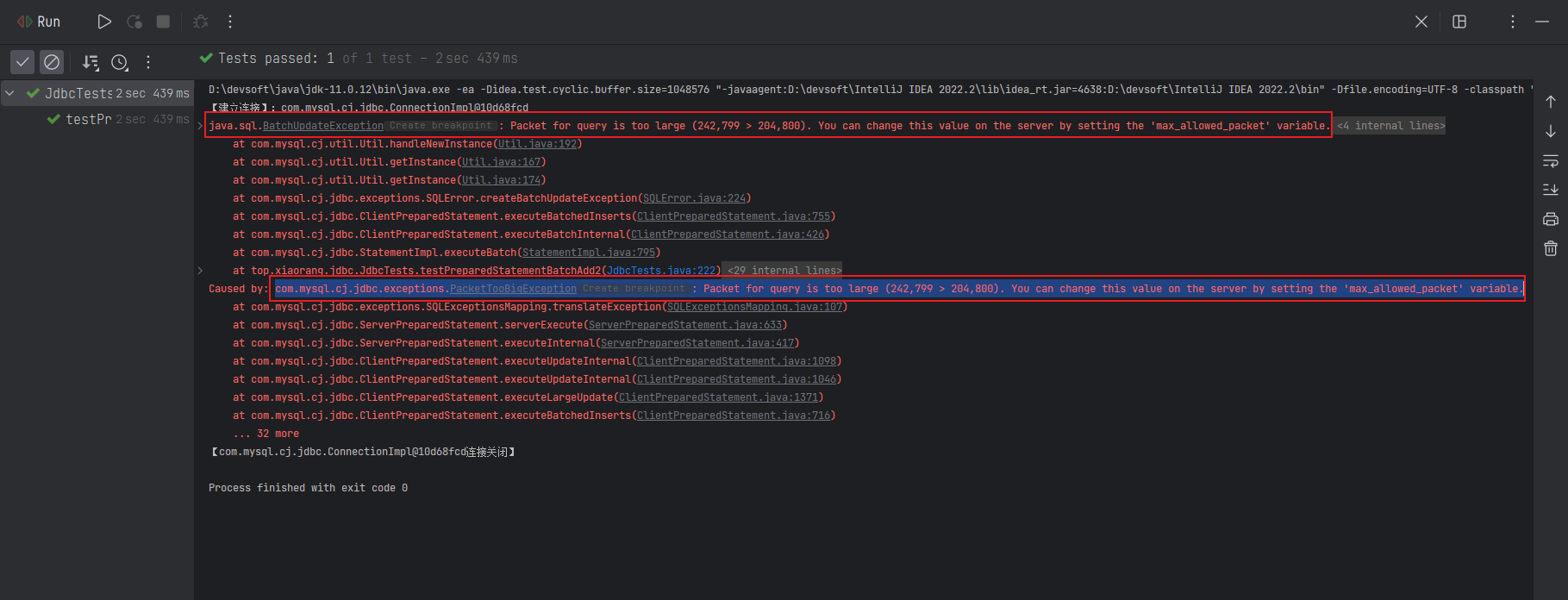
那么该怎么优化代码呢?其实很简单,咱们分批次处理,一次处理 500 条数据,代码优化如下:
@Test
public void testPreparedStatementBatchAdd3() {
long start = System.currentTimeMillis();
try {
CONNECTION.setAutoCommit(false);
String sql = "INSERT INTO `user`(`name`, `age`, `birthday`, `salary`, `note`) VALUES(?, ?, ?, ?, ?)";
try (PreparedStatement preparedStatement = CONNECTION.prepareStatement(sql)) {
for (int i = 1; i < 1000000; i++) {
preparedStatement.setString(1, "小白" + i);
preparedStatement.setInt(2, 18);
preparedStatement.setDate(3, new Date(new java.util.Date().getTime()));
preparedStatement.setFloat(4, 18000.0f);
preparedStatement.setString(5, "销售");
preparedStatement.addBatch();
if (i % 500 == 0) {
preparedStatement.executeBatch();
preparedStatement.clearBatch();
}
}
preparedStatement.clearBatch();
CONNECTION.commit();
LOGGER.info("百万条数据插入用时:{}【单位:毫秒】", (System.currentTimeMillis() - start));
}
} catch (SQLException e) {
e.printStackTrace();
try {
CONNECTION.rollback();
} catch (SQLException ex) {
throw new RuntimeException(ex);
}
}
}点击测试,等待一段时间后,发现插入成功!测试结果如下所示:
查看数据库中用户表的数据,发现已全部成功插入!
事务
MySQL 对事务的支持
Tip
对于 MySQL 中事务不清楚的小伙伴的可以查看 MySQL四种隔离级别演示 这篇文章,文章中详细地介绍了 MySQL 事务特性以及 MySQL 的四种隔离级别。
JDBC 事务处理
在 JDBC 中的事务是使用 Connection 实例对象的 commit() 方法和 rollback() 方法来管理的。在 JDBC 中事务的默认提交时机,如下:
- 当一个连接对象被创建时,默认情况下是自动提交事务,每次执行一条 SQL 语句时,如果执行成功,就会向数据库自动提交,此操作不能回滚。
- 关闭数据库连接,数据就会自动提交。如果多个操作,每个操作使用的是自己单独的连接 (Connection),则无法保证事务。同一个事务的多个操作必须在同一个连接下。
在 JDBC 中使用事务的基本步骤如下:
- 调用
Connection实例对象的setAutoCommit(false)方法以取消自动提交事务。 - 在所有的 SQL 语句都成功执行后,调用
commit()方法提交事务。 - 在出现异常时,调用
rollback()方法回滚事务。 - 若此时
Connection没有被关闭,还可能被重复使用,则需要恢复其自动提交状态setAutoCommit(true)。
测试
Tip
为了方便观察运行效果,下面的操作每次执行前都将删除已有的 user 表,并重新创建 user 表,这样自动编号将从 1 开始。然后插入三条初始数据。
INSERT INTO `user`(`name`, `age`, `birthday`, `salary`, `note`) VALUES('小让', 18, '1995-07-13', 16000.0, '程序员');
INSERT INTO `user`(`name`, `age`, `birthday`, `salary`, `note`) VALUES('小星', 18, '1995-03-20', 20000.0, '幼教');
INSERT INTO `user`(`name`, `age`, `birthday`, `salary`, `note`) VALUES('三十', 25, '1995-08-08', 22000.0, '硬件工程师');可以看到用户 1 的薪资为 16000,用户 2 的薪资为 20000,现在咱们就模拟一个场景,让用户 1 的薪资减 1000,然后让用户 2 的薪资加 1000,两个过程作为一个整体,总的薪资应该不变,其实就是模拟的转账过程。
没有事务的情况
@Test
public void testTransferNonTransaction() {
String sql1 = "UPDATE `user` SET `salary` = `salary` - ? WHERE `uid` = ?;";
String sql2 = "UPDATE `user` SET `salary` = `salary` + ? WHERE `uid` = ?;";
try (PreparedStatement preparedStatement = CONNECTION.prepareStatement(sql1);
PreparedStatement preparedStatement2 = CONNECTION.prepareStatement(sql2)) {
preparedStatement.setFloat(1, 1000.0f);
preparedStatement.setInt(2, 1);
preparedStatement.executeUpdate();
int i = 1 / 0;
preparedStatement2.setFloat(1, 1000.0f);
preparedStatement2.setInt(2, 2);
preparedStatement.executeUpdate();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}测试结果如下所示:出现异常。
然后查看数据库用户表中的数据: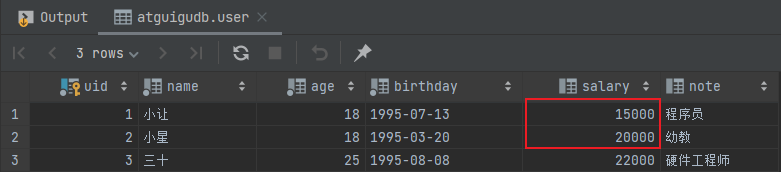
发现在没有事务并且出现异常的情况下,用户 1 已经扣了 1000,但是用户 2 并没有加 1000,此时就暴露出没有事务的危险性。
存在事务的情况
@Test
public void testTransferWithTransaction() throws SQLException {
connection.setAutoCommit(false);
try {
String sql1 = "UPDATE `user` SET `salary` = `salary` - ? WHERE `uid` = ?;";
PreparedStatement preparedStatement1 = connection.prepareStatement(sql1);
preparedStatement1.setFloat(1, 1000.0f);
preparedStatement1.setInt(2, 1);
preparedStatement1.executeUpdate();
int i = 1 / 0;
String sql2 = "UPDATE `user` SET `salary` = `salary` + ? WHERE `uid` = ?;";
PreparedStatement preparedStatement2 = connection.prepareStatement(sql2);
preparedStatement2.setFloat(1, 1000.0f);
preparedStatement2.setInt(2, 2);
preparedStatement2.executeUpdate();
connection.commit();
} catch (Exception e) {
e.printStackTrace();
connection.rollback();
}
}测试结果如下所示:出现异常。
然后查看数据库用户表中的数据: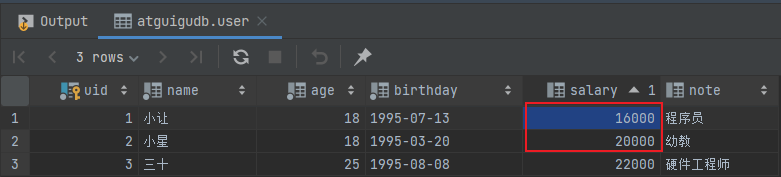
发现在增加事务之后,即使在出现异常的情况下,也不会发生用户 1 已经扣 1000,而用户 2 没有加钱的尴尬情况。
数据库连接池
为什么需要数据库连接池?
传统的 jdbc 开发形式存在的问题:
- 普通的 JDBC 数据库连接使用【DriverManager】来获取,每次向数据库建立连接的时候都要将 【Connection】加载到内存中,再验证用户名和密码(保守估计需要花费 0.05s~1s 的时间)。
- 需要【数据库连接】的时候,就向数据库申请一个,执行完成后再【断开连接】。这样的方式将会消耗大量的资源和时间。数据库的连接资源并没有得到很好的重复利用。若同时有几百人甚至几千人在线,频繁的进行数据库连接操作将占用很多的系统资源,严重的甚至会造成服务器的崩溃。
- 对于每一次数据库连接,使用完后都得断开。否则,如果程序出现异常而未能关闭,将会导致数据库系统中的内存泄漏,最终将导致重启数据库。(回忆:何为 Java 的内存泄漏?)
- 这种开发方式不能控制【被创建的连接对象数】,系统资源会被毫无顾及的分配出去,如连接过多,也可能导致内存泄漏,服务器崩溃。
为解决传统开发中的数据库连接问题,可以采用数据库连接池技术。
- 数据库连接池的基本思想:就是为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。
- 数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个。
- 数据库连接池在初始化时将【创建一定数量】的数据库连接放到连接池中。无论这些连接是否被使用,连接池都将一直保证至少拥有一定量的连接数量。连接池的【最大数据库连接数】限定了这个连接池能占有的最大连接数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。
优点
(1)资源重用
由于数据库连接得以重用,避免了频繁创建,释放连接引起的大量性能开销。在减少系统消耗的基础上,另一方面也增加了系统运行环境的平稳性。
(2)更快的系统反应速度
数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于连接池中备用。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而减少了系统的响应时间。
(3)新的资源分配手段
对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接池的配置,实现某一应用最大可用数据库连接数的限制,避免某一应用独占所有的数据库资源。
(4)统一的连接管理,避免数据库连接泄漏
在较为完善的数据库连接池实现中,可根据预先的占用超时设定,强制回收被占用连接,从而避免了常规数据库连接操作中可能出现的资源泄漏。
常见的开源数据库连接池
【DataSource】通常被称为【数据源】,它包含【连接池】和【连接池管理组件】两个部分,习惯上也经常把 DataSource 称为连接池。
【DataSource】用来取代 DriverManager 来获取 Connection,获取速度快,同时可以大幅度提高数据库访问速度。DataSource 同样是 jdbc 的规范,针对不通的连接池技术,我们可以有不同的实现。
特别注意:
- 数据源和数据库连接不同,数据源无需创建多个,它是产生数据库连接的工厂,通常情况下,一个应用只需要一个数据源,当然也会有多数据源的情况。
- 当数据库访问结束后,程序还是像以前一样关闭数据库连接:conn.close(); 但 conn.close() 并没有关闭数据库的物理连接,它仅仅把数据库连接释放,归还给了数据库连接池。
Druid(德鲁伊)
Druid 是阿里巴巴开源平台上一个数据库连接池实现,它结合了 C3P0、DBCP、Proxool 等 DB 池的优点,同时加入了【日志监控】,可以很好的监控 DB 池连接和 SQL 的执行情况,可以说是针对监控而生的 DB 连接池,可以说是目前最好的连接池之一。
- 引入依赖
- 编写配置文件
- 测试用例
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.8</version>
</dependency>druid.url=jdbc:mysql://localhost:3306/atguigudb?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&useServerPrepStmts=true&cachePrepStmts=true&allowPublicKeyRetrieval=true&rewriteBatchedStatements=true
druid.username=root
druid.password=123456
druid.initialSize=10
druid.minIdle=20
druid.maxActive=50
druid.maxWait=500public class DruidDataSourceTest {
private static final Logger LOGGER = LoggerFactory.getLogger(DruidDataSourceTest.class);
private static DataSource dataSource = null;
@BeforeAll
public static void before() {
try {
Properties properties = new Properties();
properties.load(DruidDataSourceTest.class.getResourceAsStream("/druid.properties"));
dataSource = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
@Test
public void testAdd() {
try (Connection connection = dataSource.getConnection()) {
Statement statement = connection.createStatement();
String sql = "INSERT INTO `user`(`name`, `age`, `birthday`, `salary`, `note`) VALUES('小让', 18, '1995-07-13', 16000.0, '程序员');";
int count = statement.executeUpdate(sql);
LOGGER.info("【数据更新行数】:{}", count);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}点击测试按钮,测试结果如下所示:
查询数据库,检验是否真的执行成功:
可以发现,数据库 user 表中确实增加了一条数据!
HiKariCP
HiKariCP 是数据库连接池的一个后起之秀,日语中“光”的意思,号称历史上最快的数据库连接池,可以完美地 PK 掉其他连接池,是一个高性能的 JDBC 连接池,在后边学习的 springboot 中默认集成了该连接池,他是由日本人 Brett Wooldridge 开发。
- 引入依赖
- 编写配置文件
- 测试用例
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>5.0.1</version>
</dependency>jdbcUrl=jdbc:mysql://localhost:3306/atguigudb?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&useServerPrepStmts=true&cachePrepStmts=true&allowPublicKeyRetrieval=true&rewriteBatchedStatements=true
username=root
password=123456
dataSource.connectionTimeout=1000
dataSource.idleTimeout=60000
dataSource.maximumPoolSize=10public class HikariDataSourceTest {
private static final Logger LOGGER = LoggerFactory.getLogger(HikariDataSourceTest.class);
private static DataSource dataSource = null;
@BeforeAll
public static void before() {
HikariConfig config = new HikariConfig("/hikari.properties");
dataSource = new HikariDataSource(config);
}
@Test
public void testAdd() {
try (Connection connection = dataSource.getConnection()) {
Statement statement = connection.createStatement();
String sql = "INSERT INTO `user`(`name`, `age`, `birthday`, `salary`, `note`) VALUES('小让', 18, '1995-07-13', 16000.0, '程序员');";
int count = statement.executeUpdate(sql);
LOGGER.info("【数据更新行数】:{}", count);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}点击测试按钮,测试结果如下所示:
查询数据库,检验是否真的执行成功:
可以发现,数据库 user 表中确实增加了一条数据!