技术碎片
foreach 循环
foreach 循环只不过是个语法糖,让咱们在遍历集合时代码更简洁明了。其实 foreach 的背后是 Iterator迭代器,为什么这么说呢?请看如下示例代码:
List<String> names = new ArrayList();
names.add("marry");
names.add("jack");
names.add("tom");
for (String name : names) {
System.out.println(name);
}反编译之后的代码如下所示:
List<String> names = new ArrayList();
names.add("marry");
names.add("jack");
names.add("tom");
Iterator var5 = names.iterator();
while(var5.hasNext()) {
String name = (String)var5.next();
System.out.println(name);
}可以看到 foreach 循环的底层使用的就是 Iterator 迭代器。
reduce()
reduce()方法对数组中的每个元素按序执行一个提供的 reducer 函数,每一次运行 reducer 会将先前元素的计算结果作为参数传入,最后将其结果汇总为单个返回值。
语法:Array.prototype.reduce() - JavaScript | MDN (mozilla.org)
reduce()
reduce(callbackFn, initialValue)参数:
callbackFn:为数组中每个元素执行的函数。其返回值将作为下一次调用callbackFn函数时的accumulator参数。对于最后一次调用,返回值将作为整个reduce()方法的返回值。该函数被调用时将传入以下参数:accumulator:累加器,上一次调用callbackFn函数的结果。在第一次调用callbackFn()函数时,如果指定了initialValue参数的话,则accumulator为指定的初始值,否则的话为数组第一个元素array[0]的值;currentValue:当前元素的值。在第一次调用callbackFn()函数时,如果指定了initialValue参数的话,则currentValue为数组第一个元素array[0]的值,否则的话为数组第二个元素array[1]的值;currentIndex:当前元素在数组中的索引位置。在第一次调用callbackFn()函数时,如果指定了initialValue参数的话,则currentIndex的值为 0,否则的话为 1;array:调用了reduce()方法的数组本身;
initialValue可选:第一次调用callbackFn回调函数时初始化accumulator的值。如果指定了initialValue参数的话,则callbackFn函数从数组中的第一个元素array[0]的值作为currentValue开始执行。如果没有指定initialValue参数的话,则accumulator初始化为数组中的第一个元素array[0]的值,并且callbackFn函数从数组中第二个元素array[1]的值作为currentValue开始执行。在这种情况下,如果数组为空(没有第一个元素array[0]的值可以作为accumulator返回),则会抛出错误;
几种常见的用法如下所示:可直接拷贝到控制台中运行查看执行结果!
数组求和
javascriptconst array = [15, 16, 17, 18, 19]; const sum = array.reduce((accumulator, currentValue, currentIndex) => { const returns = accumulator + currentValue; console.log(`accumulator: ${accumulator}, currentValue: ${currentValue}, index: ${currentIndex}, returns: ${returns}`); return returns; }); console.log(sum);分组
javascriptconst people = [ { name: "Alice", age: 21 }, { name: "Max", age: 20 }, { name: "Jane", age: 20 }, ]; const grouped = people.reduce((obj, current) => { let array = obj[current.age] || []; array.push(current); obj[current.age] = array; return obj; }, {}); console.log(grouped);去重
javascriptconst array = ["a", "b", "a", "b", "c", "e", "e", "c", "d", "d", "d", "d"]; const arrayWithNoDuplicates = array.reduce((accumulator, current) => { if (!accumulator.includes(current)) { return [...accumulator, current]; } return accumulator; }, []); console.log(arrayWithNoDuplicates);
利用 IntelliJ IDEA 生成可运行的 JAR 包
具体步骤如下所示:
配置项目输出路径:确保你的项目的输出路径正确配置为
out或target目录。这将是生成 JAR 文件的位置。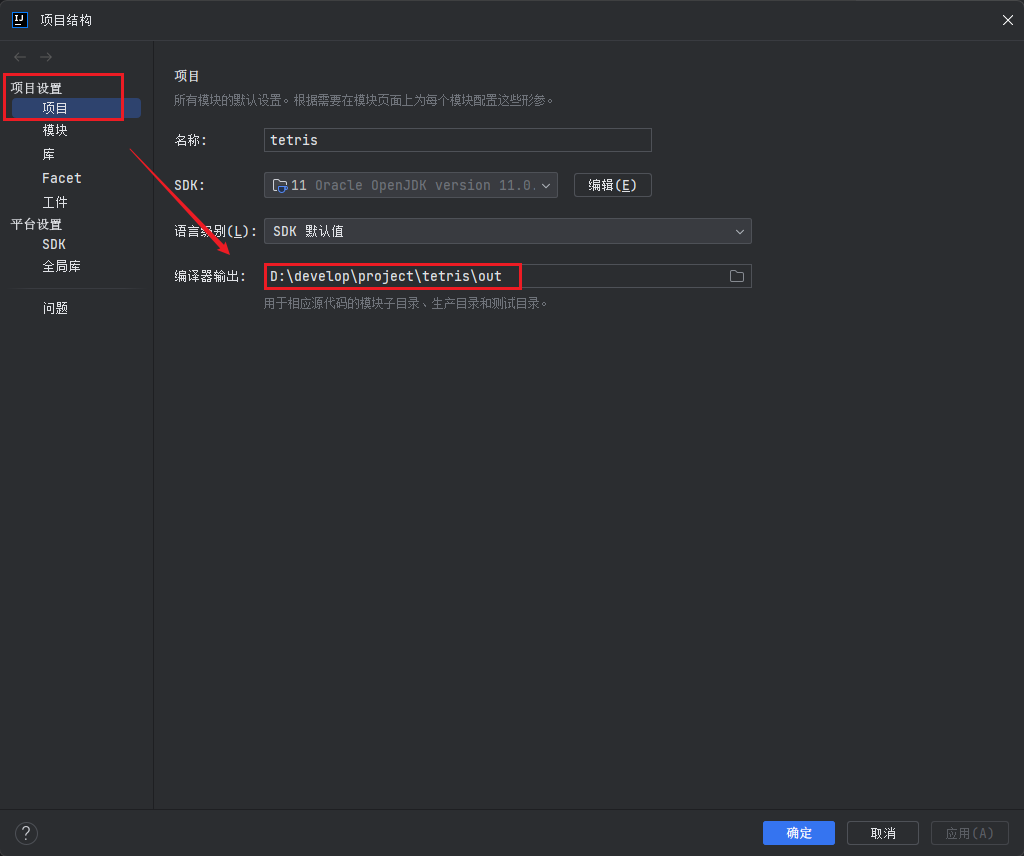
- 在项目窗口中,右键单击项目的根文件夹,然后选择 "Open Module Settings"(或者使用快捷键
F4); - 在弹出的窗口中,选择 "Project" 标签;
- 在 "Project compiler output" 部分,确保输出路径设置正确;
- 在项目窗口中,右键单击项目的根文件夹,然后选择 "Open Module Settings"(或者使用快捷键
编译项目:在 IntelliJ IDEA 中,使用以下步骤编译项目:
- 点击菜单栏中的 "Build" 或 "Build Project";
- 或者使用快捷键,通常是
Ctrl + F9(Windows/Linux)或Cmd + F9(macOS);
这将触发项目的编译,将编译输出放置在配置的输出路径中。
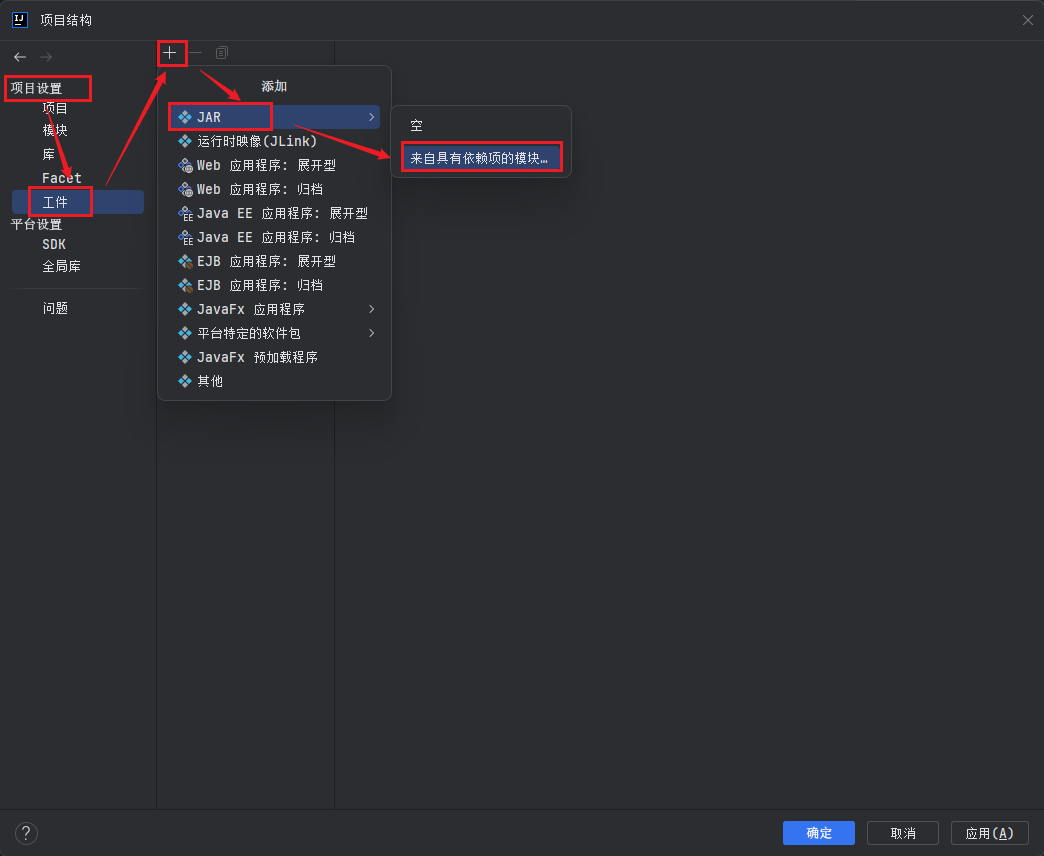
创建可运行 JAR 文件:在 IntelliJ IDEA 中,使用以下步骤创建可运行的 JAR 文件:
- 打开 "File" 菜单,选择 "Project Structure";
- 在左侧面板中,选择 "Artifacts";
- 点击右侧的 "+" 图标,然后选择 "JAR" > "From modules with dependencies...";
- 在弹出窗口中,选择项目的主类(包含
public static void main(String[] args)方法的类);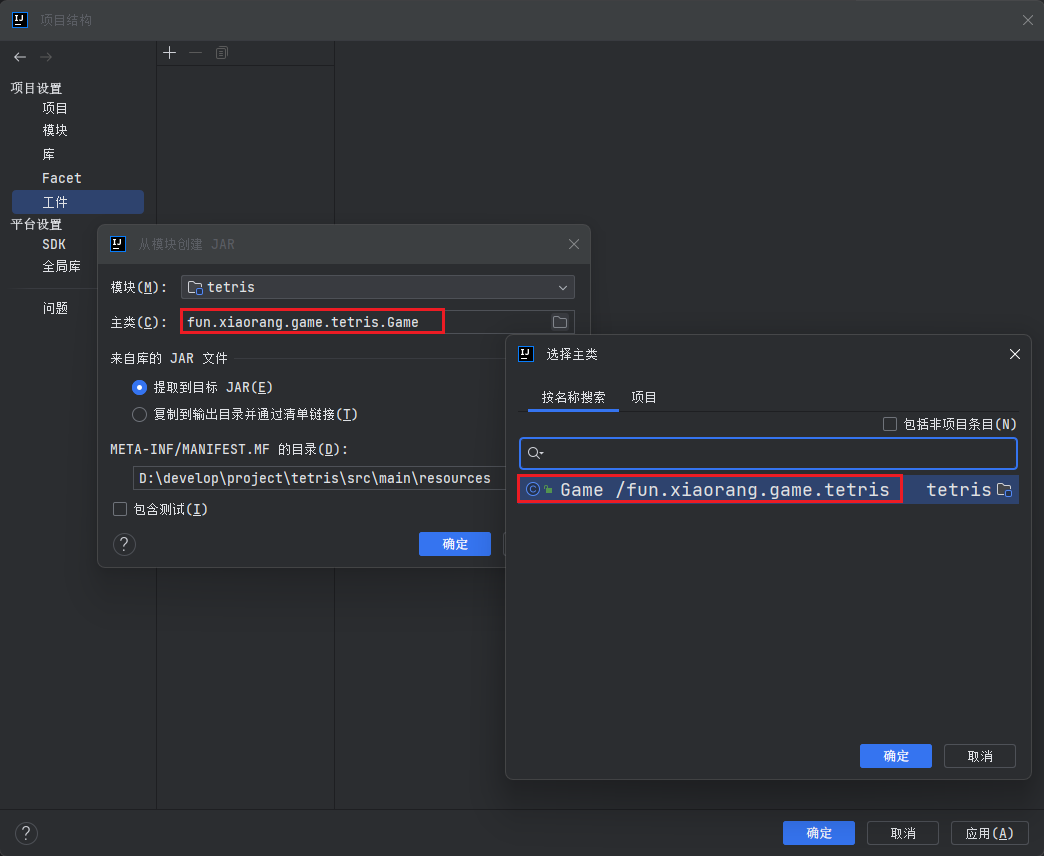
- 在 "JAR files from libraries" 部分,确保所有依赖项都被包含在 JAR 文件中(默认情况下应该已经勾选了);
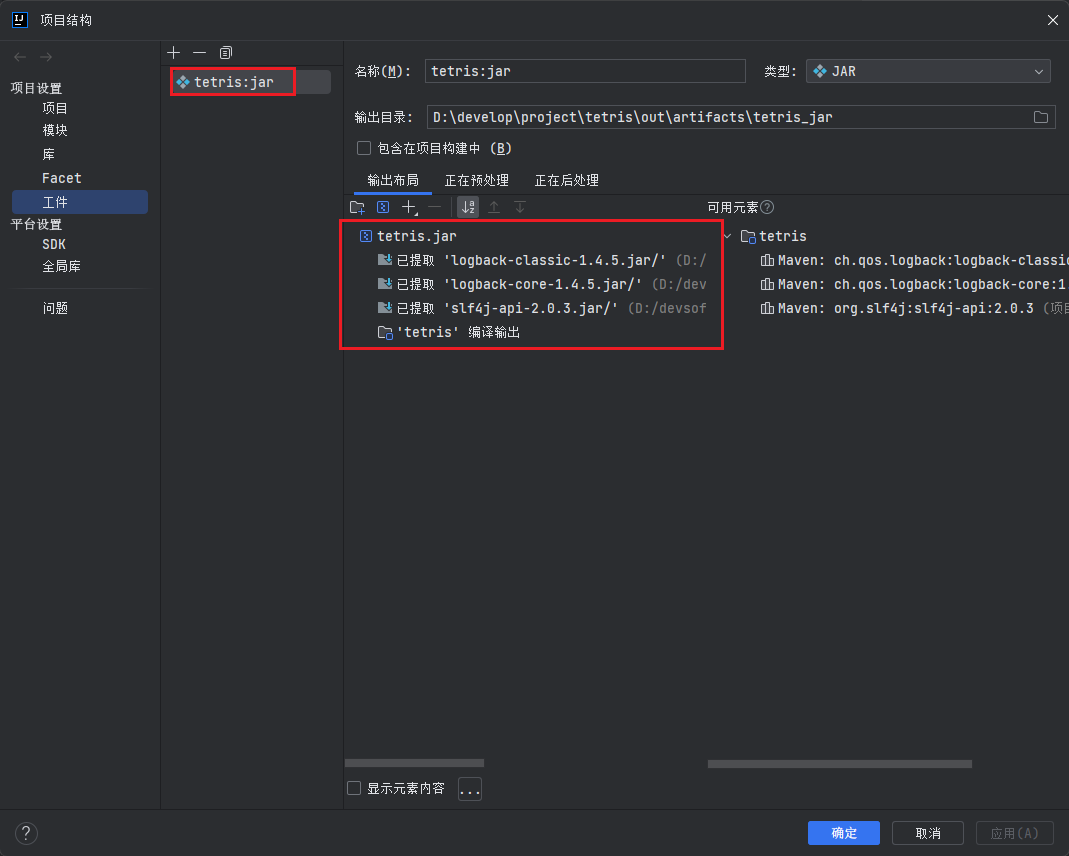
- 点击 "OK";
构建 JAR 文件:在 IntelliJ IDEA 中,使用以下步骤构建 JAR 文件:
- 点击菜单栏中的 "Build" > "Build Artifacts";
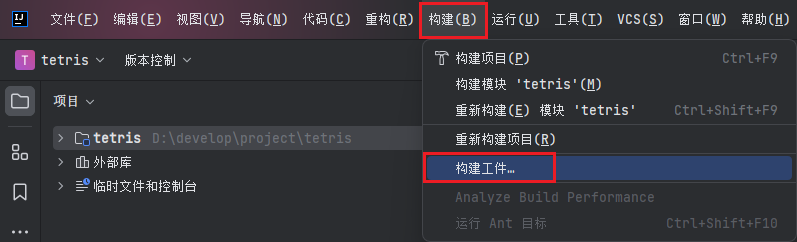
- 选择你刚刚创建的 JAR 配置(通常是项目的名称);
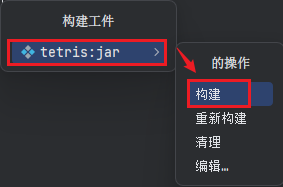
- 这将触发 JAR 文件的构建,并将生成的 JAR 文件放置在输出路径中;
- 点击菜单栏中的 "Build" > "Build Artifacts";
查找可执行 JAR 文件:生成的可执行 JAR 文件将被放置在输出路径中,可以在
out或target目录下找到该 JAR 文件。
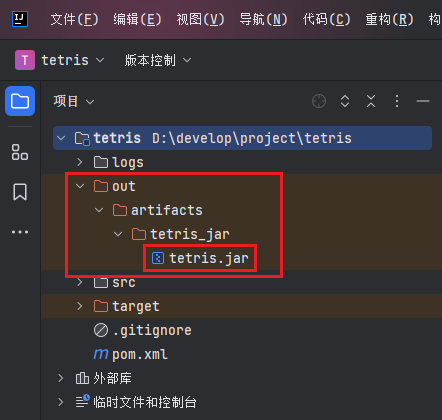
运行可执行 JAR 文件:在终端中使用以下命令来运行生成的可执行 JAR 文件:
bashjava -jar your-project-name.jar替换
your-project-name为实际的 JAR 文件名即可!
如此,即可在 IntelliJ IDEA 中直接生成和运行可执行的 JAR 文件,而无需使用其他 Maven 插件。
mapper 文件不生效的原因以及解决方案
原因:默认情况下,在 src/main/java 目录下的 xxxMapper.xml 文件在编译时并没有被正确复制到类路径中。
解决方案:配置 pom.xml 文件中的 <build> 部分的 resources 配置,用于定义该如何处理项目中的资源文件,如下所示:
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.*</include>
</includes>
<filtering>true</filtering>
</resource>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
</resources>
</build>- 当设置
<filtering>true</filtering>时,表示要启用资源过滤。这意味着 Maven 会在将资源复制到目标目录之前,解析并替换资源文件中的占位符或属性。这对于将配置信息动态注入到资源文件中非常有用,例如将版本号、数据库连接信息等替换到配置文件中。 - 当设置
<filtering>false</filtering>时,表示禁用资源过滤。资源文件将以原样复制到目标目录,不会执行任何替换操作。
在 Maven 项目中,你可以在 <build> 部分的 <resources> 配置中设置 <filtering> 为 true,并在资源文件中使用 ${property} 或 @property@ 这样的占位符,然后在 Maven 的构建过程中,这些占位符会被替换为实际的属性值或配置信息。
举个栗子,在 src/main/resources 目录中有一个配置文件 application.properties,其中包含如下内容:
database.url=@db.url@
database.username=@db.username@如果你在 pom.xml 中设置了 <filtering>true>,并在 Maven 的 <properties> 中定义了 db.url 和 db.username 的值,那么 Maven 会在构建过程中替换 @db.url@ 和 @db.username@ 为实际的值,然后再将这个文件复制到目标目录。这允许你根据不同环境的需要自定义配置文件。
try-with-resources 自动关闭资源
try-with-resources 是 Java 7 引入的一个语言特性,用于自动关闭实现 java.lang.AutoCloseable 接口的资源,例如文件流、数据库连接、网络连接等。这个特性的目的是简化资源管理和减少资源泄漏的风险。使用 try-with-resources 可以更加优雅地处理资源的关闭,无需手动编写 finally 块来确保资源的释放。它有助于避免资源泄漏,提高代码的可读性和稳定性。
try-with-resources 还支持多个资源的同时管理,你可以在 try 后面的括号中列出多个资源,它们会按照声明的顺序从后往前依次关闭资源,确保资源的正确关闭和释放。举个栗子,如下所示:
try (ResourceType1 resource1 = new ResourceType1();
ResourceType2 resource2 = new ResourceType2()) {
// 在这个块中使用资源1和资源2
// 当块结束时,资源2会首先关闭,然后是资源1
} catch (Exception e) {
// 异常处理
}如果 try-with-resources 块中关闭资源的 close() 方法抛出异常,会发生如下两种情况:
- 关闭资源的异常(Suppressed Exception):当资源的
close()方法抛出异常时,这个异常不会中断程序的执行。相反,它会被捕获,然后以一个 " 被抑制的异常 " 的形式存储在主异常中,主异常继续传播。 - 主异常:主异常是在
try-with-resources块内部的代码中抛出的异常,它是最初引发close()方法异常的原因。主异常会继续传播,可以由上层代码捕获和处理。
为了处理资源的 close() 方法抛出的异常,你可以使用以下方式:
try (ResourceType resource = new ResourceType()) {
// 使用资源
} catch (Exception e) {
// 主异常处理
Throwable[] suppressed = e.getSuppressed();
for (Throwable t : suppressed) {
// 处理被抑制的异常
}
}在上面的示例中,当主异常被捕获时,你可以使用 getSuppressed() 方法来获取被抑制的异常,然后处理它们。被抑制的异常通常代表了资源关闭时的问题,例如文件无法正常关闭或数据库连接出现问题。
需要注意的是,资源的 close() 方法抛出的异常通常不应该中断程序的执行,而应该被记录并处理,以确保资源得到适当的关闭和释放。处理被抑制的异常是一种优雅的方式来管理资源的关闭异常,同时保持程序的稳定性。
数据源配置
druid
spring:
datasource:
username: root
password: root
url: jdbc:mysql://localhost:3306/jwt_security?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
druid:
# 初始化时建立物理连接的个数
initialSize: 5
# 连接池的最小空闲数量
minIdle: 10
# 连接池最大连接数量
maxActive: 20
# 获取连接时最大等待时间,单位毫秒
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 300000
# 配置一个连接在池中最大生存的时间,单位是毫秒
maxEvictableIdleTimeMillis: 900000
# 检测连接是否有效的sql
validationQuery: SELECT 1 FROM DUAL
# 申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效
testWhileIdle: true
# 申请连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为true
testOnBorrow: false
# 归还连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为true
testOnReturn: false
# 开启游标缓存
poolPreparedStatements: true
# 最大打开游标数量
maxPoolPreparedStatementPerConnectionSize: 20
# 合并多个DruidDataSource的监控数据
useGlobalDataSourceStat: true
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,stat: 监控统计、waLL: 防御sqL注入
filter:
stat:
# 数据库类型,这里可以配置为mysql、oracle、sqlserver、postgresql等
db-type: mysql
# 慢sql记录的毫秒数
slow-sql-millis: 2000
# 是否启用慢sql记录日志
log-slow-sql: true
# 是否合并sql
merge-sql: true
wall:
config:
# 是否允许删除语句
delete-allow: false
# 界面过滤器,依赖于上方配置stat
web-stat-filter:
# 是否启用WebStatFilter默认值true
enabled: true
# 匹配所有请求
url-pattern: "/*"
# 忽略资源
exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"
# 提供监控统计界面访问
stat-view-servlet:
# 是否启用StatViewServlet默认值true
enabled: true
# 访问路径为/druid时,跳转到StatViewServlet
url-pattern: "/druid/*"
# 登录用户名
login-username: admin
# 登录密码
login-password: 123456
# IP白名单(没有配置或者为空,则允许所有访问)
allow: 127.0.0.1
# IP黑名单(共同存在时,deny优先于allow)
deny:
# 是否开启统计数据重置
reset-enable: falsehikari
spring:
datasource:
username: root
password: root
url: jdbc:mysql://localhost:3306/jwt_security?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.zaxxer.hikari.HikariDataSource
# hikari连接池配置
hikari:
#连接池名
pool-name: HikariCP
#最小空闲连接数
minimum-idle: 5
# 空闲连接存活最大时间,默认10分钟
idle-timeout: 600000
# 连接池最大连接数,默认是10
maximum-pool-size: 10
# 此属性控制从池返回的连接的默认自动提交行为,默认值:true
auto-commit: true
# 此属性控制池中连接的最长生命周期,值0表示无限生命周期,默认30分钟
max-lifetime: 1800000
# 数据库连接超时时间,默认30秒
connection-timeout: 30000
# 连接测试query
connection-test-query: SELECT 1SpringBootTest 找不到组件报错的原因以及解决方案
原因
封装一个 common-redis 的公共模块组件,具体实现步骤如下所示:
引入依赖;
xml<dependencies> <!-- Redis --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies>在该模块中存在如下两个组件:
RedisConfig和RedisService;java@Configuration @AutoConfigureBefore(RedisAutoConfiguration.class) public class RedisConfig { @Bean public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory lettuceConnectionFactory) { RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>(); redisTemplate.setConnectionFactory(lettuceConnectionFactory); final StringRedisSerializer stringRedisSerializer = new StringRedisSerializer(); redisTemplate.setKeySerializer(stringRedisSerializer); // 使用Jackson2JsonRedisSerializer来序列化和反序列化redis的value值 final Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class); final ObjectMapper objectMapper = new ObjectMapper(); // 指定要序列化的域,field,get和set,以及修饰符范围,ANY是都有包括private和public objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); // 指定序列化输入的类型,类必须是非final修饰的,final修饰的类,如 public final class User implements Serializable {} 则会抛出异常 objectMapper.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, ObjectMapper.DefaultTyping.NON_FINAL); jackson2JsonRedisSerializer.setObjectMapper(objectMapper); redisTemplate.setValueSerializer(jackson2JsonRedisSerializer); redisTemplate.setHashKeySerializer(stringRedisSerializer); redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer); redisTemplate.afterPropertiesSet(); return redisTemplate; } }java@RequiredArgsConstructor @Component public class RedisService { private final RedisTemplate<String, Object> redisTemplate; /** * 设置缓存 * * @param key 键 * @param value 值 * @param timeout 过期时间(秒) */ public void set(@NonNull final String key, @NonNull final Object value, @NonNull final long timeout) { redisTemplate.opsForValue().set(key, value, timeout, TimeUnit.SECONDS); }为了使这两个组件生效,需要在 resources 资源目录下创建
META-INF/spring.factories文件,文件内容如下所示:org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ fun.xiaorang.common.redis.config.RedisConfig,\ fun.xiaorang.common.redis.service.RedisService单元测试:验证
RedisService是否能够正常使用;java@SpringBootTest class RedisServiceTest { private final RedisService redisService; @Autowired RedisServiceTest(final RedisService redisService) { this.redisService = redisService; } @Test void set() { redisService.set("test", "123456", 20); } }运行测试方法时,发现报如下错误:
Warning
java.lang.IllegalStateException: Unable to find a @SpringBootConfiguration, you need to use @ContextConfiguration or @SpringBootTest(classes=...) with your test
说没有找到
@SpringBootConfiguration注解,需要使用@ContextConfiguration注解或@SpringBootTest注解来解决该错误!因此咱们需要在@SpringBootTest注解中指定这两个组件 ➡️@SpringBootTest(classes = {RedisConfig.class, RedisService.class})。再次进行测试,测试结果依旧报错!错误信息如下所示:
Caution
Caused by: org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type 'org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory' available: expected at least 1 bean which qualifies as autowire candidate. Dependency annotations: {}
说找不到
LettuceConnectionFactory组件!不对呀!咱们不是引入了spring-boot-starter-data-redis依赖吗?根据自动配置原理,在RedisAutoConfiguration自动配置类中导入了LettuceConnectionConfiguration配置类,java@Configuration(proxyBeanMethods = false) @ConditionalOnClass(RedisOperations.class) @EnableConfigurationProperties(RedisProperties.class) @Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class }) public class RedisAutoConfiguration {在
LettuceConnectionConfiguration配置类中不是往 Spring 容器中注入了一个LettuceConnectionFactory的组件吗?怎么还会报LettuceConnectionFactory组件找不到呢?java@Configuration(proxyBeanMethods = false) @ConditionalOnClass(RedisClient.class) @ConditionalOnProperty(name = "spring.redis.client-type", havingValue = "lettuce", matchIfMissing = true) class LettuceConnectionConfiguration extends RedisConnectionConfiguration { @Bean @ConditionalOnMissingBean(RedisConnectionFactory.class) LettuceConnectionFactory redisConnectionFactory( ObjectProvider<LettuceClientConfigurationBuilderCustomizer> builderCustomizers, ClientResources clientResources) { LettuceClientConfiguration clientConfig = getLettuceClientConfiguration(builderCustomizers, clientResources, getProperties().getLettuce().getPool()); return createLettuceConnectionFactory(clientConfig); }
解决方案
在咱们平时的 SpringBoot 项目中,都会在启动类上加一个 @SpringBootApplication 注解,该注解定义如下所示:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(excludeFilters = { @Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {可以看到在该注解上又标注了一个 @EnableAutoConfiguration 注解,用于开启自动配置功能。这样的话,项目中任意一个 spring-boot-starter 依赖中的组件都会被扫描到 Spring 容器中。因此咱们有如下两种解决方案:
在与当前测试类同级或上级的地方写一个启动类,如下所示:
java@SpringBootApplication public class CommonRedisApplication { public static void main(String[] args) { SpringApplication.run(CommonRedisApplication.class, args); } }在当前测试类上标注
@EnableAutoConfiguration注解,如下所示:java@EnableAutoConfiguration @SpringBootTest(classes = {RedisConfig.class, RedisService.class}) class RedisServiceTest { private final RedisService redisService; @Autowired RedisServiceTest(final RedisService redisService) { this.redisService = redisService; } @Test void set() { redisService.set("test", "123456", 20); } }
Maven 插件统一修改聚合工程项目版本号
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>versions-maven-plugin</artifactId>
</plugin>该插件已被 spring-boot-dependencies 所管理,因此直接引入即可,无需额外添加版本号。
使用 mvn versions:set -DnewVersion=0.0.1-SNAPSHOT 命令修改项目的版本号,修改成功后,所有模块的版本号都会变成 0.0.1-SNAPSHOT。
默认情况下(generateBackupPoms=true),会生成 pom.xml.versionsBackup 备份文件, 此时如果觉得修改的不对,可以使用 mvn versions:revert 进行回滚。
查看修改之后的 pom.xml 文件,觉得没有问题,就可以使用 mvn versions:commit 命令进行确认,该命令会删除修改版本号时生成的备份文件。
可以使用 mvn versions:set -DnewVersion=0.0.1-SNAPSHOT -DgenerateBackupPoms=false 命令直接修改版本号无需确认。如果你设置 generateBackupPoms=false,则直接修改 pom.xml 文件,不会生成备份文件,也就无法回退版本号,也就不需要使用 commit 命令再次确认。
Warning
在修改版本号之前,必须保证父子模块的版本号一致,如果之前手动修改过父模块的版本号导致父子模块的版本号不一致,此时使用插件统一修改项目的版本号是不成功的!会抛出如下错误:子模块中 parent 的版本号与父模块中的 version 版本号不一致! 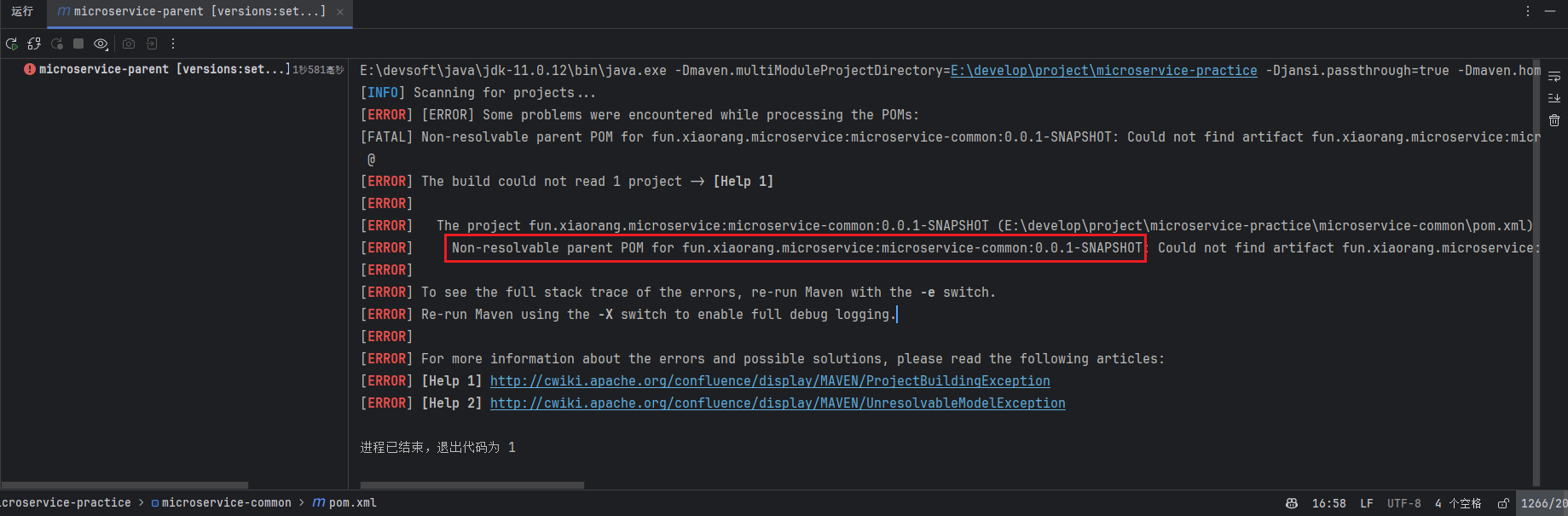
Tip
此时需要先将父模块的 version 版本号改回来,变成和子模块中 parent 的版本号一致,才能使用插件统一修改,否则的话修改不成功!
Logback 配置文件
对于日志功能的要求:
- 要能够展示加载配置时的调试信息,当发生解析配置文件出错时,可以快速定位问题
- 要能够自动定时检测配置文件的变化,并重新应用
- 日志要能够按天滚动,每天生成日志
- 单个日志文件不超过 512MB,超过的生成新文件
- 设置存储时间(90天)、空间上限(10GB),不能无限制存储日志文件
- 将 INFO 级别的日志与 ERROR 级别的日志分开,可以快速看到每一天是否产生了错误,并且 INFO 级别的日志文件中要包含 ERROR 级别的日志,这样在排查问题时可以看到完整的异常发生链路
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="true" scan="true" scanPeriod="60 seconds">
<!-- 自定义日志输出格式 -->
<property name="LOG_PATTERN" value="%d{HH:mm:ss.SSS} [%thread] %highlight(%-5level) %cyan(%logger{36}) - %msg%n"/>
<!-- 自定义日志输出路径 -->
<property name="LOG_NAME" value="logs"/>
<!-- 自定义单个日志文件大小,超过将生成新的日志文件 -->
<property name="LOG_MAX_FILE_SIZE" value="512MB"/>
<!-- 自定义日志最大存留天数 -->
<property name="LOG_MAX_HISTORY" value="90"/>
<!-- 自定义日志总大小,超过将删除最旧存档 -->
<property name="LOG_TOTAL_SIZE_CAP" value="10GB"/>
<!-- 控制台输出 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${LOG_PATTERN}</pattern>
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- INFO 级别的文件日志, 按大小和时间滚动,保留 90 天,单个日志文件最大 512MB,总日志大小 10GB,输出的文件中会包含 INFO 级别以及以上(WARN 和 ERROR)的日志 -->
<appender name="FILE_INFO_LOG" class="ch.qos.logback.core.rolling.RollingFileAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>${LOG_NAME}/info.%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxFileSize>${LOG_MAX_FILE_SIZE}</maxFileSize>
<maxHistory>${LOG_MAX_HISTORY}</maxHistory>
<totalSizeCap>${LOG_TOTAL_SIZE_CAP}</totalSizeCap>
</rollingPolicy>
<encoder>
<pattern>${LOG_PATTERN}</pattern>
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- ERROR 级别的日志,按大小和时间滚动,保留 90 天,单个日志文件最大 512MB,总日志大小 10GB,输出的文件中只包含 ERROR 级别的日志 -->
<appender name="FILE_ERROR_LOG" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!--自定义输出时的级别过滤器 对于低于 ERROR 级别的日志 全部拒绝-->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>ERROR</level>
</filter>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>${LOG_NAME}/error.%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxFileSize>${LOG_MAX_FILE_SIZE}</maxFileSize>
<maxHistory>${LOG_MAX_HISTORY}</maxHistory>
<totalSizeCap>${LOG_TOTAL_SIZE_CAP}</totalSizeCap>
</rollingPolicy>
<encoder>
<pattern>${LOG_PATTERN}</pattern>
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- 根记录器,有效级别为 INFO,所有的日志都会输出到 STDOUT 和 FILE_INFO_LOG 和 FILE_ERROR_LOG 三个地方 -->
<root level="info">
<appender-ref ref="STDOUT"/>
<appender-ref ref="FILE_INFO_LOG"/>
<appender-ref ref="FILE_ERROR_LOG"/>
</root>
</configuration>微信测试号
为方便开发者开发和体验小程序、小游戏的各种能力,开发者可以申请小程序或小游戏的测试号,并使用此账号在开发者工具创建项目进行开发测试,以及真机预览体验。
申请测试号
申请测试号的过程非常简单。只需访问 申请地址 ,并使用微信扫描二维码,即可获得为自己分配好的小程序和小游戏测试账号。
登录测试号
申请成功后,进入 微信公众平台首页,扫描登录二维码,选择已有的小程序测试号或小游戏测试号登录即可。